O viés de seleção dos entrevistados pode impactar os resultados das recentes pesquisas de opinião?
Quando somente 5 em cada 100 pessoas aceitam responder a pesquisas, as amostras precisam ser corretamente calibradas para refletir o perfil social político e econômico da sociedade

O princípio mais importante para assegurar a qualidade de uma pesquisa de opinião é a chance igual de seleção na amostra de todos os membros da população estudada, ou seja, a seleção completamente aleatória dos entrevistados. Porém, na prática, nenhuma pesquisa consegue garantir inteiramente esse princípio, independentemente do modo de coleta (presencial, telefônico ou via web). Pessoas doentes e que precisam ficar em casa ou que moram em regiões perigosas ou muito remotas podem não ser alcançadas pelos entrevistadores de uma pesquisa presencial; pessoas sem telefone ou acesso à Internet não serão alcançadas pelas pesquisas com coleta telefônica ou web. Caso um entrevistado tenha tido uma probabilidade maior de ser ouvido por uma empresa de pesquisa do que uma pessoa que não está dentro da amostra, essa seleção não pode ser considerada aleatória ― é o conceito da chamada seleção não aleatória. Mas é possível adotar procedimentos metodológicos para corrigir este tipo de desvio, incorporando nas amostras pessoas com um perfil muito próximo aos respondentes que não podem ser alcançados.
Um outro desafio em relação à seleção aleatória dos entrevistados são as possíveis diferenças sistemáticas entre as pessoas que aceitam responder às pesquisas e as que não aceitam ou desistem de preencher as respostas. No caso das pesquisas telefônicas ou via web, a taxa média de resposta observada internacionalmente é de aproximadamente 5%. Isso quer dizer que para cada 5 pessoas que aceitam responder uma pesquisa de opinião, 95 não aceitam. A estratificação das amostras por cota demográfica (gênero, região, renda, etc.) é importante para corrigir as possíveis diferenças entre as pessoas que acabaram respondendo e as pessoas que não quiseram responder. No entanto, este procedimento pode ser insuficiente: dentro de cada cota amostral pessoas mais engajadas politicamente, por exemplo, podem responder as pesquisas com uma probabilidade maior, gerando um viés de seleção.
Em um artigo recente publicado no EL PAÍS, apontei a existência de evidências de que as últimas pesquisas Datafolha podem ter sido impactadas por este tipo de viés. Na pesquisa do dia 3 de abril, a distribuição amostral dos votos reportados para o segundo turno da eleição de 2018 exagerou em 15 pontos a margem de vitória do presidente Jair Bolsonaro. O resultado da disputa em votos válidos foi Jair Bolsonaro 55% contra Fernando Haddad 45%. Na pesquisa do Datafolha de 3 de abril, no entanto, a distribuição da amostra apontava para 63% dos votos para Jair Bolsonaro contra 37% para Haddad, uma diferença de mais de 25 pontos entre eles, em vez dos 10 pontos apurados nas urnas.
Mesmo admitindo que falhas de memória e um eventual viés subjetivo das pessoas pode fazer com que a lembrança do voto passado não reflita perfeitamente o resultado real, a diferença observada é extremamente problemática por dois motivos: primeiro, ela é muito maior do que o teto normalmente identificado na literatura acadêmica; segundo, ela é muito maior em relação às últimas pesquisas presenciais do próprio Datafolha. Em um artigo recente no Jota, Felipe Nunes e Fernando Meirelles também manifestam preocupação em relação a um potencial viés de seleção nas amostras Datafolha, na opinião deles relacionado à taxa de não resposta por faixa de renda.
Na resposta do Datafolha ao meu artigo, o instituto afirma que “o voto declarado é uma variável tão subjetiva que historicamente muda de acordo com a percepção do eleitorado sobre expectativas e satisfação com a gestão do candidato vitorioso.” Se é verdade que uma grande parte da população altera a declaração do voto passado em relação à popularidade atual do presidente, muitos que passaram a reprovar a atuação dele não reconhecerão mais o seu voto. Neste caso, o percentual de arrependimento entre eleitores do Bolsonaro será muito subestimado por definição. No entanto, o Datafolha afirma numa análise recente que 17% dos eleitores do Bolsonaro estão arrependidos. Ou o Datafolha tem razão que a base utilizada para o cálculo desse percentual é uma variável tão subjetiva que subestimaria por definição o resultado que foi divulgado, ou o argumento central feito na resposta publicada no EL PAÍS é exagerado.
O Datafolha também diz que “o autor calcula votos válidos sem a base completa da variável na amostra. Desconsidera a taxa de não resposta, repercentualizando-a de maneira proporcional pelos candidatos.” No entanto, o cálculo dos votos válidos somente leva em consideração votos afirmativos e é isso o que o próprio Datafolha sempre fez em relação a esse cálculo no passado. O objeto do cálculo apresentado no meu artigo era somente uma parcela específica da amostra: a fatia da população brasileira que votou no segundo turno de 2018, e que não se encontra na amostra Datafolha com a mesma distribuição do resultado dessa eleição.
O instituto explica que “a pergunta sobre o voto na eleição de 2018 não deve ser utilizado como variável de controle ou ponderação.” Mas, baseado nas discussões metodológicas na literatura acadêmica, considero que o voto de 2019 deveria ser utilizado como variável de controle para identificar e corrigir padrões de seleção não aleatória, investigando tanto a diferença entre o voto declarado na amostra e o resultado de 2018, quanto também a volatilidade dessa dimensão na série temporal.
Também afirma que “Não é a falta de eleitores de determinado candidato na amostra que determina uma melhor ou pior avaliação do mandatário, mas sim o contrário ―quando um governante apresenta bom desempenho, a probabilidade da população dizer que votou nele é maior.” É possível excluir da amostra todos os eleitores de Fernando Haddad e não observar nenhum impacto sobre a avaliação de Jair Bolsonaro? Provavelmente não. O Datafolha tem toda razão em apontar o problema de identificação pelo possível impacto da popularidade do presidente sobre a declaração do voto passado. No entanto, as correlações observadas na sua série temporal não corroboram com a especulação sobre o impacto da causalidade reversa: caso o efeito dominante fosse o do impacto da popularidade do presidente sobre o voto passado e não vice-versa, o impacto observado no voto declarado deveria ser muito maior do que a série temporal aparenta.
Há pelo menos três resultados do Datafolha que poderiam estar impactados pela seleção não-aleatória dos respondentes, não somente nas pesquisas telefônicas, mas também nas presenciais, resultados que na opinião deste autor são implausíveis:
1. Na última pesquisa divulgada no dia 28 de abril, o Datafolha registrou uma forte queda de aprovação do presidente Jair Bolsonaro em relação às pesquisas mais recentes desde março: a aprovação do seu desempenho em relação ao coronavírus caiu 8 pontos de 35% (dado reportado 23-mar) para 27%. O percentual que rechaça o impeachment caiu numa velocidade ainda maior: 9 pontos de 59% (dado reportado 04-abr) para 50%. No entanto, mesmo depois dessa queda, o percentual de aprovação “Ótimo e bom” do Governo Bolsonaro subiu 3 pontos desde a pesquisa de dezembro. Não foi esclarecido qual foi a razão da decisão de omitir a avaliação do governo da divulgação de março e de duas outras pesquisas em abril.
A única forma de reconciliar as tendências reportadas pelo Datafolha é de observar que o percentual de aprovação “Ótimo e bom” deve ter crescido muito mais que 33% antes do fim de abril. O gráfico abaixo faz uma projeção sobre o patamar de aprovação “Ótimo e bom” do Governo implicado pelas estimativas divulgadas pelo Datafolha para o mês de março: 41 pontos. Observando as correlações existentes, não há nenhum motivo para especular que a curva de aprovação do Governo Bolsonaro ia ter seguido uma trajetória muito diferente dos outros dois indicadores incluídos no gráfico. É plausível que, com a crise do coronavírus, o governo do presidente Bolsonaro tinha 41% de “Ótimo e bom” no final de março, 11 pontos a mais que em dezembro?
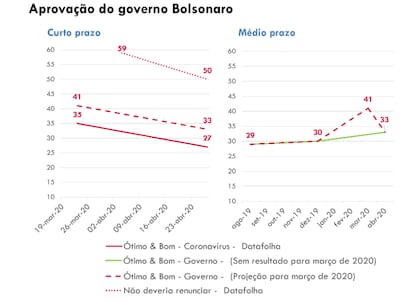
O Datafolha não esclareceu qual foi a razão da decisão de não incluir essa pergunta sobre avaliação do Governo na divulgação de março e de duas outras pesquisas em abril. É uma pergunta chave de todas as pesquisas de avaliação do Governo conduzidas pelo Datafolha desde 1986.
2. Também na última pesquisa divulgada no dia 28 de abril, o Datafolha mediu a popularidade do ex-ministro de Justiça Sergio Moro e achou um nível de desaprovação “Ruim e péssimo” de somente 7 pontos. Na série temporal de várias pesquisas (Atlas, XP/Ipespe, e do próprio Datafolha), esse nível é extremamente correlacionado com a taxa de apoio ao ex-presidente Lula e de rechaço a sua prisão, nunca registrando um nível abaixo de 20%. Mesmo assumindo que o rompimento com Jair Bolsonaro pode ter melhorado a imagem de Sergio Moro entre eleitores de esquerda, a magnitude do movimento indicado pela pesquisa Datafolha não parece plausível.
3. Na pesquisa de agosto de 2019, o Datafolha concluiu que se o segundo turno da eleição entre Jair Bolsonaro e Fernando Haddad acontecesse naquele momento, Fernando Haddad venceria o pleito. No entanto, este cenário somente foi medido numa pesquisa cuja distribuição amostral para a votação no Haddad no segundo turno da eleição de 2018 era a mais favorável entre todas as pesquisas da série Datafolha: somente 11 pontos de vantagem para Jair Bolsonaro em comparação com os 25 pontos de vantagem observados na distribuição amostral de março.
Sobre a metodologia das pesquisas Atlas, entendo que uma comparação entre a qualidade metodológica das nossas organizações em nada agrega na aferição técnica do problema apontado. Todas as pesquisas Atlas contêm uma ficha técnica com a distribuição amostral dos dados coletados e uma seleção de cruzamentos considerados relevantes. Antes da divulgação do artigo anterior, me coloquei à disposição do Datafolha para oferecer mais informações caso isso fosse útil na investigação dos problemas apontados. Ao contrário do que foi indicado na sua resposta, Datafolha não disponibiliza as bases de dados com as respostas coletadas e vem restringindo os dados sobre composição amostral, como ilustrado pela exclusão da composição do voto de 2018 da sua pesquisa de 3 de abril (o relatório divulgado inicialmente foi alterado). A qualidade das pesquisas Atlas é confirmada por acertos que podem ser verificados no noticiário internacional: única pesquisa entre mais de 15 institutos a acertar dentro da margem de erro o resultado da eleição presidencial argentina de 2019; segunda melhor pesquisa das primárias argentinas; melhor desempenho médio entre mais de 50 organizações de pesquisa no ciclo das primárias democratas deste ano; as melhores pesquisas das primárias democratas da Califórnia, Flórida e New Hampshire.
Por fim, seria importante que Datafolha esclarecesse ao público alguns aspectos metodológicos, como o nível e o perfil da taxa de não-resposta das suas pesquisas telefônicas, os procedimentos para identificar o viés de seleção e os resultados dos seus testes, entre outros.
Andrei Roman é CEO da Consultoria Atlas, Ph.D. em Ciência Política pela Universidade Harvard.









































